|
Understanding through Discussion |
|
|
Register | Sign In |
|
QuickSearch
| Thread ▼ Details |
|
Thread Info
|
|
|
| Author | Topic: Introduction to Genetics | ||||||||||||||||||||||||||||||||||||||||||||
|
Taq Member  Posts: 10033 Joined: Member Rating: 5.3
|
If you have some cells of some creature but don't know what creature it is, is it always easy to identify it from its DNA?
At one time the answer would have been "No". In order to identify a species by their DNA you need DNA from a known source. Not too long ago (i.e. 20 years ago) there simply wasn't a lot of DNA sequence known. Luckily, methodologies and technologies have greatly increased our ability to sequence DNA akin to Moore's Law and computer chips. If you are trying to work on identifying the species then a larger BAC clone would be the way to go. In this methodology you use an enzyme to break up the DNA into large chunks (or physical shearing), and then randomly insert those chunks into the BAC plasmid. You then use Sanger sequencing from the known plasmid sequences that flank the insert of interest. This usually gives 300 to 700 bases of good read from both ends of the insert. In the olden days we used radioactive terminators and autoradiography from big gels to run these sequencing reactions. Now it is all automated on capillary gels that use fluorescent dyes instead. The results of the run will look something like this:
Once you have your sequence you then dump it into BLAST. If it is not able to find a perfect match for your sequence it will give a phylogeny of the closest related sequences so you will at least be able to see what kind of critter you are working with. With some luck, you may even be able to identify not only the species, but where in the genome that DNA chunk came from.
If you have DNA from strikingly different breeds of, say, dogs, say a greyhound, a chihuahua, a black lab, a Bichon Frise, a Dalmation, or take your pick of what are the least similar -- are you able to tell which is which from just looking at the DNA and what exactly do you look for? Not without a lot of background work. You would first need to find breed specific sequences from each of those breeds which takes a lot of work. At best, you could determine if another dog is the parent/sibling of another dog assuming you had the STR data needed for such an analysis. You may want to read about human DNA fingerprinting to get a better idea of how this would work: DNA profiling - Wikipedia
Do you ever actually look at the DNA itself or are you looking at some sort of indicator, model, or whatever you call it that you somehow derive from the cell? I know a DNA portrait as it were is often represented by some sort of bars that to me are indecipherable. Do I have to learn what those mean in order to get answers to the sort of questions I'm asking? Most sequencing uses Sanger sequencing (as cited above). DNA profiling uses PCR to amplify short tandem repeats (STR's), and the gel then separates these short sequences by size. Those will produce the bands you see on some of those gels, such as this one: http://www.pbs.org/...so/resources/guide/earthappenact3.html There is also RFLP techniques that look at larger chunks of DNA and how they are chopped up by different enzymes: http://faculty.clintoncc.suny.edu/...sis/rflp%20analysis.htm IOW, there are many ways of doing DNA fingerprints, and not all of them require direct sequencing. PCR and endonucleases are two indispensible tools used in this type of work, so if you want to understand what is going on you should really learn what those tools are and how they are used. I will get to the other material when I have a chance.
|
||||||||||||||||||||||||||||||||||||||||||||
|
Taq Member Posts: 10033 Joined: Member Rating: 5.3
|
Apparently the DNA in different body cells is different. Can you nevertheless identify the creature from any of these different cells? Or, what SORT of difference are we talking about?
There are cells that are anucleated such as the red blood cell that lacks a nucleus. Gametes will only have half of your genome as per the process of meiosis. Other than that, I am unaware of cells that have "different DNA". The only differences that you will see are epigenetic differences which are patterns of DNA methylation and histone packaging. However, the DNA will still have the same sequence from cell to cell.
The function of some genes is known, and can even be predicted across different species. That is, you know where the gene for oh say eye color is located, or the many genes that determine eye color if there is more than one, and this is predictable for many species. Or is it? It is usually not a matter of location but of sequence similarity. Genes can move around quite a bit due to recombination events. Synteny and orthology are still important, but for pure protein function the only bit that counts is the sequence. Location tends to be more important for DNA regulation, that is when a gene is turned on and how strongly it is expressed. DNA regulation has as much to do with what an animal looks like as basic protein function.
Generally speaking, are there many traits that are governed by more than one gene? For metazoans, this is definitely the case. You may want to look into "Evolutionary Developmental Biology". It is a huge field of study that looks at just that, the interaction of genes that give rise to different traits as a product of embryonic development.
Where is the "junk DNA" located on the DNA strand? Is it interspersed with functioning genes or collected all in one place or what? Is there some way you can tell by just looking at it that it's "junk" or how do you tell? Junk DNA is spread throughout the genome. The most obvious examples are processed pseudogenes which carry obvious evidence of past function that has been knocked out by subsequent mutations. One example is the human vitamin C synthase pseudogene which prevents us from producing our own vitamin C. This is why we need to eat vitamin C to prevent scurvy. There are also old transposons and just long strings of DNA that have no identifiable features, be it a promoter, transcription factor, or open reading frame. A lot of these stretches of junk DNA can be identified by comparing one species to another. Using some basic assumptions you can determine the rate at which different areas of the genome are accumulating mutations. If the accumulation is consistent with neutral drift then the chances are that there is no DNA sequence specific function in that part of the genome.
Homozygosity is the pairing of identical forms of the gene, is that right? Does that mean an absolutely identical chemical sequence on both sides of the pair? These were initially identified as the same phenotype. As you are probably aware, two alleles can differ in DNA sequence but still produce the same physical trait (and even the same protein sequence). So the answer is yes and no. You just have to be aware of the comparison being made.
|
||||||||||||||||||||||||||||||||||||||||||||
|
Taq Member Posts: 10033 Joined: Member Rating: 5.3
|
So you are apparently giving a yes to this question because now it is possible, by the various means you mention (that are technically rather over my head), to find out at leastwhat kind of critter you are working with. I gather it’s not easy at all since it does require quite a bit of technical work to arrive at the conclusion but that you CAN indeed find out the species.
To sum it up briefly, technology has made it much easier and faster to sequence genomes so many more genomes have been sequenced. This makes it easier to determine which species a given DNA sequence came from, or at least a species group (e.g. genus or family). A social security number could serve as an analogy here. If all we had was the first number of a SSN it would be difficult to figure out who it belonged to. The more numbers we have the more we can narrow it down. There are still groups of species that we do not have much sequence data from, but for many groups it is equivalent to having all but one number of a SSN which allows us to really narrow it down. As to the technical details, I included links so you could check it out yourself. It is a bit difficult to explain these techniques in a forum format. All I can do is encourage you to do some extended searches on some of those keywords if they interest you. I am sure there are some good videos on Sanger sequencing, as one example. A new technology is pyrosequecing which is really interesting as well. This technique is often used on ancient DNA that is made up of many short pieces of DNA.
I am a bit surprised because I did assume that the number of chromosomes would be the major indicator, which I also assumed wouldn’t be hard to determine, but you didn’t address that part of the question. I guess I ignored it because it is a very minor indicator. Chromosome number can vary even within species, but can be the same between very distantly related species (I believe that tobacco plants and humans have the same number of chromosomes while our closest ape relative has one more than we do). The sequence is way more important for determining relatedness.
|
||||||||||||||||||||||||||||||||||||||||||||
|
Taq Member Posts: 10033 Joined: Member Rating: 5.3 |
Didn't want to let things get out of order here but maybe it's OK as long as the subtitles identify the topic. I really would like to know about "Junk DNA" and was going to skip to that question anyway when I saw Dr. A's post with the diagram of the Human Genome here: EvC Forum: Flood Geology: A Thread For Portillo It doesn't even mention Junk DNA. Can you explain?
Labelling something as "junk DNA" doesn't tell us a whole lot about it. It doesn't tell us what function it may have had (e.g. pseudogenes), if it is associated with genes (e.g. introns), if the junk DNA came from transposons, etc. Also, a transposon (SINE's and LINE's) can be junk DNA and it can also have function as a regulator of surrounding genes. The chart that Dr. A used was focusing more on the idea of alleles which focus more on the protein coding sections of the genome which only account for 3% of the genome. It was not meant to show how much junk DNA there is.
ABE: The Wikipedia article on Noncoding DNA seems to suggest that the term Junk DNA applies to all DNA that does not produce protein. That's a very poor description since transcription factors are noncoding DNA but they have very important functions and are nothing close to junk DNA. I would classify junk DNA as disposable non-coding DNA. That is, if that DNA were removed or it's sequence randomly changed it would not have a perceptible effect on phenotype or fitness. Many ERV's, transposons, and pseudogenes would fall under this category while important DNA regulators would not.
I don't see an indication of what percentage of the Genome is pseudogenes. Most estimates I have seen are in the ballpark of 20,000 to 75,000 pseudogenes in the human genome. Not sure about the number of bases, but I can't image that it is much more than coding DNA at about 3% (maybe as high as 10% or as low as 1%?). sfs might have more info on that since he was directly involved in the human genome project (and was an author on the human genome paper if memory serves). But of course, all of this comes down to the question of whether a stretch of DNA has important function, and that isn't completely determined by the DNA sequence alone. You need more data which the ENCODE project is currently working on. "The National Human Genome Research Institute (NHGRI) launched a public research consortium named ENCODE, the Encyclopedia Of DNA Elements, in September 2003, to carry out a project to identify all functional elements in the human genome sequence."http://www.genome.gov/10005107 However, ENCODE suffers from salesmanship, IMHO. In their latest publication they are claiming that 80% of the genome has a "biochemical function". This is a much, much lower bar than my definition used above ("disposable non-coding DNA"). If a stretch of DNA is made into RNA then ENCODE classifies it has having function, even if that RNA transcript has no effect on fitness or phenotype. I have often used the analogy of real trash in your kitchen. Your kitchen trash releases odor molecules into the air in your kitchen which ENCODE would classify as a function since it alters the biochemistry of your kitchen. IOW, ENCODE would classify real trash as not trash. What they have done is define "function" in such a way that it becomes irrelevant. I think sfs has the same opinion, as do most biologists I have talked to. That is why I am accusing ENCODE of salesmanship since they are trying to make their data look more important than it really is.
|
||||||||||||||||||||||||||||||||||||||||||||
|
Taq Member Posts: 10033 Joined: Member Rating: 5.3
|
Faith,
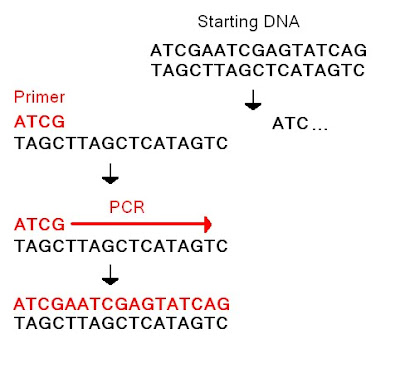
You seem to have questions about the basics of DNA chemistry, so I thought I would start with the basics of the molecule itself. First, the backbone of DNA is made up of sugars linked together by phosphate groups as seen here:
Notice the numbering on the carbons (those are the carbons that make up the sugar portion of the molecule). The orientation of the carbons, phosphates, and base give DNA a "direction". Enzymes read DNA in what is called the "5' to 3' direction". To use an analogy, the 5' sugar serves as the capital letter at the start of a sentence which allows the reader to read in the correct direction. This is a bit hard to understand, but it is important when trying to figure out how PCR works, and how DNA is replicated. Next, let's focus on the nitrogenous bases. As someone mentioned earlier, bases are complementary. A's match up to T's and G's match up to C's. Why is this? Because of their biochemistry. A's and T's have 2 available hydrogen bonds while G's and C's have 3 available hydrogen bonds. This allows G's and C's to stick together and A's and T's to stick together. You can see how the whole thing lines up here:
Notice that the strands go in opposite "directions", with 5' to 3' going down on the left side and 5' to 3' going up on the right side. Also notice how the hydrogen bonds line up between the A's and T's and the G's and C's. So with DNA we have two backbones running up each side of the ladder in opposite directions, and the rungs of the ladder are complementary bases that bind to each other through a specific number of hydrogen bonds. All of the technologies we are talking about take advantage of these basic features. PCR uses small chunks of DNA called primers that bind to the complementary bases like a key in a lock. This allows you to target a specific section of DNA. For example:
You will notice that the primer is the complementary sequence to the strand below it. This allows it to specifically bind to that section of DNA. Enzymes then extend the DNA, matching the complementary strand base by base. Once the copying is done you heat the DNA which separates the strands (i.e. "breaks" the hydrogen bonds). This allows the primers to bind to the same spot again and create a new strand. Again, this all happens in the 5' to 3' direction on both strands so you will have copying going on in opposite directions on both strands. Confusing, I know. It takes a while to get these concepts down, but those are the basics. Just to stress this again, the important features are the direction of the backbone (5' to 3') and the complementary nature of the bases (A-T, G-C). Others should feel free to clarifiy or fix any mistakes I have made.
|
||||||||||||||||||||||||||||||||||||||||||||
|
Taq Member Posts: 10033 Joined: Member Rating: 5.3 |
3) "Bulking out" one's genome with genetic "noise" serves to minimize the effect of frameshift mutations by spreading out the genes.
It also serves as a sponge for external mutagens such as radiation or chemical mutagens. DNA may also serve as actual physical support for the cell, which may explain why the lowly amoeba has a genome that is hundreds of times larger than our own. The concept of junk DNA really comes down to the question you are asking. For a lot of geneticists, they want to know if a sequence is under purifying selection. If it is not, then it is considered junk DNA even if it serves as structural support or as a sponge for mutations. I think this definition fits well in most evo v. creo discussions.
|
||||||||||||||||||||||||||||||||||||||||||||
|
Taq Member Posts: 10033 Joined: Member Rating: 5.3 |
And by "purifying selection", you mean "natural selection against mutations"?
Negative selection is probably the easiest to detect, but my population genetics is not the greatest so feel free to correct me on that one.
|
||||||||||||||||||||||||||||||||||||||||||||
|
Taq Member Posts: 10033 Joined: Member Rating: 5.3
|
The question that brought me back to this thread is really a wish to know what differentiates the genome of one species from another. The answer is the order of nucleotides on the DNA strands.
Like they say there is only about 5% difference between the human genome and the chimp genome. That means that when you compare 2 homologous strands of DNA there will be the same base 19 out of 20 times when comparing the two genomes.
That 5% of the human genome then must contain the coding for what is specifically human and not ape, and same with the ape genome. The 5% difference between chimps and humans also contains the chimp specific mutations that differentiate them from the other apes. It is also worth mentioning that we are the chimps closest relative. Chimps share more DNA with us than they do with the other apes, such as gorillas and orangutans. If chimp DNA is ape DNA, then we are apes, too.
But is that particular 5% even recognizable, is it clear in the genome where it is located and what it codes for? It is easily recognizable once the sequencing and assembly is done. It is as simple as doing a BLAST search using nucleotide sequence from one species to query the genome of another species. BLAST: Basic Local Alignment Search Tool
In other words I'd really like to know the specifics about that part of every genome for every creature that differentiates it from all the others. What makes a cat genome a cat genome, a dog genome a dog genome etc? The differences are going to be found throuhgout the billions of bases in the genome. Perhaps it would help if I show a specific example. What I did was copy a smaller chunk of DNA sequence from human chromosome 1. You can find the entire sequence of chromosome 1 here: Homo sapiens chromosome 1, GRCh38.p14 Primary Assembly - Nucleotide - NCBI Next, I went to the BLAST page for the chimp genome, which can be found here: Nucleotide BLAST: Search nucleotide databases using a nucleotide query I pasted the copied portion of the human genome into the query sequence box at the top of the page, then clicked on the BLAST button towards the bottom of the page. I got one hit back, and here is a screen cap of the alignment between human (query) and chimp (subject) genomic DNA:
Edited by Taq, : No reason given. Edited by Taq, : No reason given.
|
||||||||||||||||||||||||||||||||||||||||||||
|
Taq Member Posts: 10033 Joined: Member Rating: 5.3 |
In short, we may know enough to look at two specific genomes and say in general this is probably a bonobo and this a human, but we do not yet know how some of these differences work. I think it is also important to point out that there are differences between one human genome and another. The HapMap project is trying to catalogue human genetic variation, and other projects are looking at the variation in different species. https://www.genome.gov/10001688 You can even zoom in to the actual sequence and find where humans differ at a given base, and the percentages of people with those variants among the pools they have tested.
|
||||||||||||||||||||||||||||||||||||||||||||
|
Taq Member Posts: 10033 Joined: Member Rating: 5.3 |
Irrespective of genes or what? How long a strand are you talking about? Yep, irrespective of genes. DNA is DNA. As to the length of strands, the human genome is broken up into 46 strands, otherwise known as chromosomes, that are open at the ends. For bacteria, they have a single circular chromosome plus a few smaller plasmids which are also circular. Think of it as bacteria having a genome like a rubber band and eukaryotes having multiple strings.
Again, my question is what is a "strand" of DNA, how long a strand, in relation to a gene for instance, or a chromosome, etc. A strand is an unbroken DNA polymer which is a continuous sugar-phosphate backbone. Below is a single strand of DNA where the pentagram structures are the sugars and the phosphates act as connectors to form the polymer. The phosphates link the 5' carbon from one sugar to the 3' carbon of the next sugar, and DNA is replicated and transcribed in the 5' to 3' direction.
Edited by Taq, : No reason given. Edited by Taq, : No reason given.
|
||||||||||||||||||||||||||||||||||||||||||||
|
Taq Member Posts: 10033 Joined: Member Rating: 5.3 |
Yeah, you're right. I always think of a "blueprint" as a set of instruction. I was using that 'or' as an i.e. But blueprints are not instructions, they're pictures, and DNA is no picture. If I were to use an analogy I would compare DNA to the gears in a clock, or the punchcards used in a Jacquard loom. "The Jacquard loom is a mechanical loom, invented by Joseph Marie Jacquard, first demonstrated in 1801, that simplifies the process of manufacturing textiles with complex patterns such as brocade, damask and matelasse.[4][5] The loom was controlled by a "chain of cards", a number of punched cards, laced together into a continuous sequence.[6] Multiple rows of holes were punched on each card, with one complete card corresponding to one row of the design."Jacquard machine - Wikipedia Edited by Taq, : No reason given.
|
||||||||||||||||||||||||||||||||||||||||||||
|
Taq Member Posts: 10033 Joined: Member Rating: 5.3 |
So a strand is basically a chromosome? Keeping in mind that DNA is double stranded . . . A chromosome is one continuous DNA molecule (with two complementary strands). Think of it like a strand of hair. If you take one strand of hair and cut it in the middle you now have two strands. Cut each again, and you have 4 strands. In fact, we use enzymes and even physical shearing to break long strands of DNA into shorter strands. "Strand" just refers to the continuous nature of the molecule.
So it's just the sequence of nucleotides irrespective of genes, and 19 out of 20 in the sequence are identical between the two species in question? Chimps and humans. As a gross oversimplification, that is the jist of it. There are also insertions and deletions, which we call indels (a mash up of the two words). This produces gaps when we try to align the two DNA sequences. You can see the indels in this alignment:
The indels are marked by the dots between the letters. The next type of difference is recombination where DNA is moved from one position in the genome to another, or even duplicated. When we compare genomes we determine if two genes are orthologs, homologs, or paralogs. An ortholog is a homologous gene found at the same spot in both genomes. A homolog is the same gene, but not necessarily in the same spot in each genome. A paralog is a duplicate gene.
But there must be different genes in the different species, no? ABE: Of course the difference in nucleotides would make for different genes, but I'm thinking of different genes as entirely different segments of DNA, entirely different locations on the strand. From what you are saying it's all the same as far as the location and order of the genes go, only the one in twenty nucleotides along the entire strand is the defining thing. /ABE I can't find the info very readily, but if memory serves, there are only a handful of genes in chimps and humans that do not have homologs in the other species. If I were to ball park it, I think there are around 20 genes in chimps that do not have homologs in humans compared to about 30,000 genes overall. If I run across the info again I will give you an update.
Is there a clearcut pattern to the location of the species-identifying nucleotides in that chain of 20? There are many patterns, enough to fill this entire paper: Initial sequence of the chimpanzee genome and comparison with the human genome | Nature . . . and then some. Overall, there are fewer differences in gene and functional non-coding regions. However, that's a bit circular since function in non-coding regions is determined by divergence rates. Perhaps it is better to say that some regions are diverging at a slower rate than others. The conserved parts of the genome are spread out all over. Suffice it to say that there are a lot of papers covering signals of selection in the human and chimp genome, so I can't really summarize it all here.
|
||||||||||||||||||||||||||||||||||||||||||||
|
Taq Member Posts: 10033 Joined: Member Rating: 5.3 |
So are you saying that the indels are the same in the same species but produce gaps in the genomes between the two species? Indels can vary between individuals within the same species. In fact, forensic scientists use indels to do DNA fingerprinting. And yes, indels are mutations. Any change in the DNA sequence is a mutation, and that includes the addition or removal of bases.
When you say "moved" or "duplicated" you are implying evolution, but I have to translate that into purely descriptive terms, which comes down to saying that the DNA in question occurs in different positions in the genome of the different species? Or is duplicate in the one but not the other? And I assume you mean as a regular feature of the genome of each? When I say moved or duplicated I am implying the observed mechanisms of DNA recombination. This wiki page has a decent overview of some of the mechanisms: Gene duplication - Wikipedia This results in multiple copies of the same DNA in the same genome.
So, trying to be sure I get this clear in my head, these different situations of the genes are considered to be identifiers of the species, that is they are predictable regular occurrences in the species genome for all individuals? They are only identifiers if they are specific to that species and common enough that a majority of the individuals have that identifier.
When you say "the same gene" I assume you mean it's a gene that makes the same trait in the organism in both species, say fingernails or eyelashes or whatever. When I say "the same gene" I mean a homologous gene as determined by sequence comparison. Homology is not determined by function with respect to DNA. Also, there is no gene for eyelashes or fingernails. Physical features are the result of interaction between many genes.
And again, homologs being genes that determine the same trait in the organism and occur in the same location on the DNA strand, Again, homology is not determined by function. It is determined by sequence. If two genes performed the same function but lacked similarity at the DNA sequence level then they would be called analogs. Genes that share DNA sequence similarity are homologs, but they don't have to be at the same position in each genome. Genes that share DNA sequence and the same position in the genome are orthologs. Genes that share sequence similarity due to a gene duplication are paralogs.
Of course an article that assumes evolution as this one does is alienating to a creationist. It is no different than a geologist assuming that the Earth is round. The evidence for shared ancestry is overwhelming, so that is the conclusion that scientists go with. The evidence in the chimp genome paper adds mountains of more evidence, such as the hundreds of thousands of orthologous ERV's shared by chimps and humans.
I wasn't sure how to describe the differences between the indels, except that if there was never any evolution between chimps and humans we can't speak of "events" so the comparison has to be merely between different locations in the genome. Your first step would be to explain why there are fewer indel differences between humans and chimps than there are between chimps and gorillas. IOW, you would have to explain why a comparison of whole genomes produces a nested hierarchy.
To me this is all pure fiction. I can't even really glean a descriptive fact from it though there must be some such facts buried in there somewhere. Is it saying that humans and chimps have the SAME fixed neutral and slightly deleterious alleles for the same genes or what? Can YOU translate this paragraph into simple descriptive terms for me? They are using population genetics to find areas of the genome that are more highly conserved than others. When they compared the chimp genome to the human genome they found that some areas were more similar than others. This indicates negative selection of mutations in the areas with less similarity. They also use variation within the human population to do the same.
Which of course implies evolution again. Fewer differences between what and what? I think the evo baggage of that abstract has thrown me. And what "function" is there in "non-coding" regions which I guess refers to pseudogenes or junk DNA that apparently retains some function or what? If you think they are wrong, then show they are wrong. Throwing out random insults is no way to approach science.
Please don't use terms like "diverging" which implies evolution and requires me to try to figure out what actual simple fact of comparison is being referred to. If you want to understand genetics then you have to understand evolution. There is no way around it.
|
||||||||||||||||||||||||||||||||||||||||||||
|
Taq Member Posts: 10033 Joined: Member Rating: 5.3 |
Can it be said that a single pair of organisms possess a vast amount of genetic variability? Or any individual? Or isn't it that you need to have a population in order to compare the individual genomes of its members to determine how much those individual genomes vary with each other? Depends on the species and the paif of organisms. A pair of human, identical twins will have nearly identical genomes and near zero variability. A pair of random humans with no recent common ancestor will have much more variability between them. A random set of chimps will have even more variability between them. A random pair of cheetahs will have very little variability because they went through a recent genetic bottleneck. For the Ark scenario, it can not be said that just 2 individuals can have the same genetic variability as a population. For example, some of the MHC genes have thousands of alleles in the human population. Each person only carries 2 alleles. A pair would only have 4 alleles between them. The only way around that is if those ark pairs were extreme polyploids, carrying thousands of copies of the genome each. As to the recent topic of neutral v. deleterious v. beneficial mutations, a gene locus with much higher variability compared to other gene loci is said to be under less selective pressure than those that are more conserved.
|
||||||||||||||||||||||||||||||||||||||||||||
|
Taq Member Posts: 10033 Joined: Member Rating: 5.3 |
Just a few friendly corrections.
Ok, so we will deal with one specific type of mutation in this post; what we call point mutations. Point mutations are changes in a single nucleotide. They fall into tree categories: substitutions are changes from one base pair to another base pair. Insertions and deletions should be self explanatory and are what Taq referred to as indels. Point mutation and substitution mutation are synonyms. Indels are not point mutations.
As you may know, a protein is encoded by a sequence of 3 amino acids (aa) that are called codons. Codons are a sequence of 3 DNA bases, not amino acids.
|
||||||||||||||||||||||||||||||||||||||||||||
|
|
Do Nothing Button
Copyright 2001-2023 by EvC Forum, All Rights Reserved
![]() ™ Version 4.2
™ Version 4.2
Innovative software from Qwixotic © 2024

 (1)
(1)